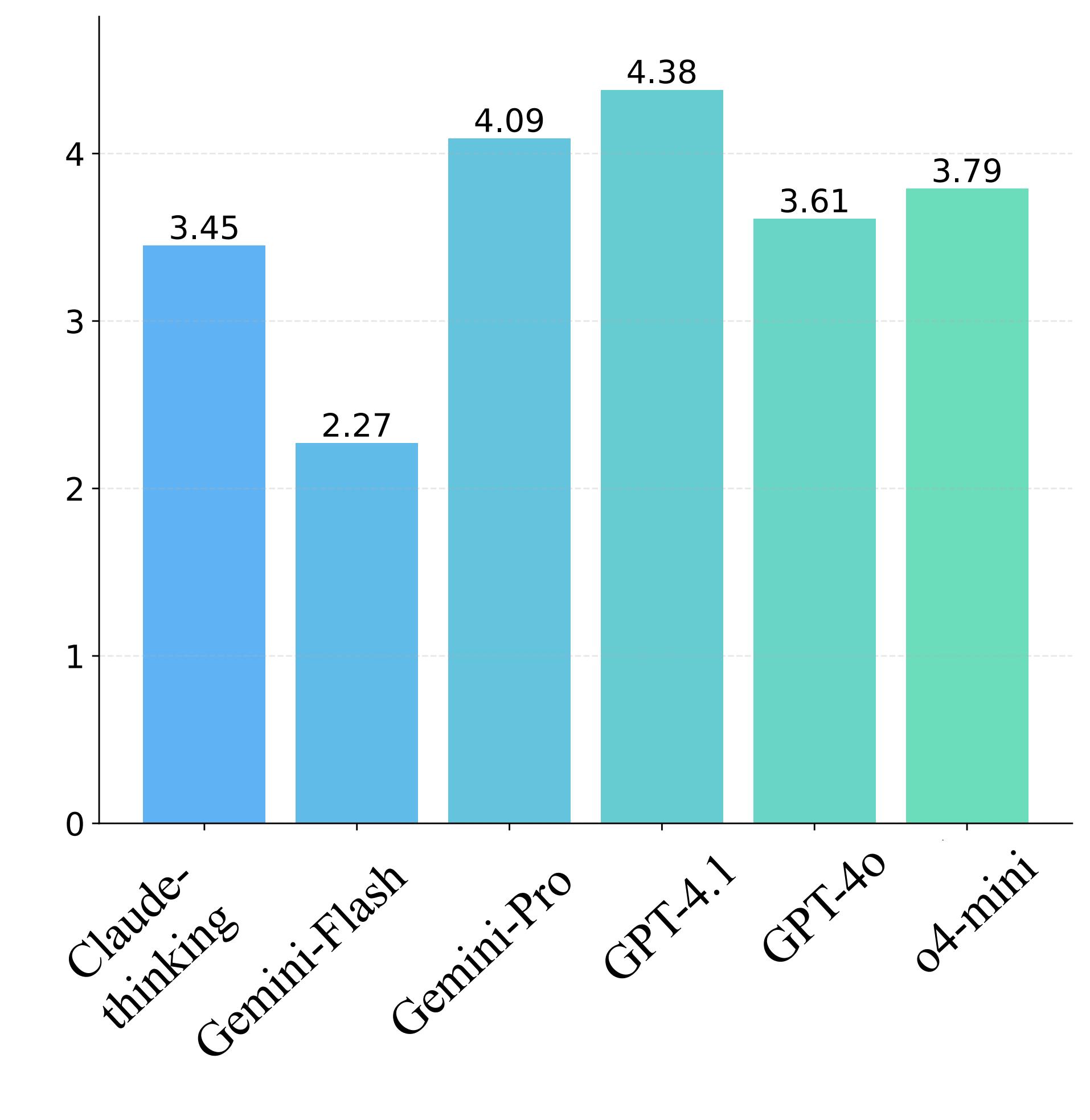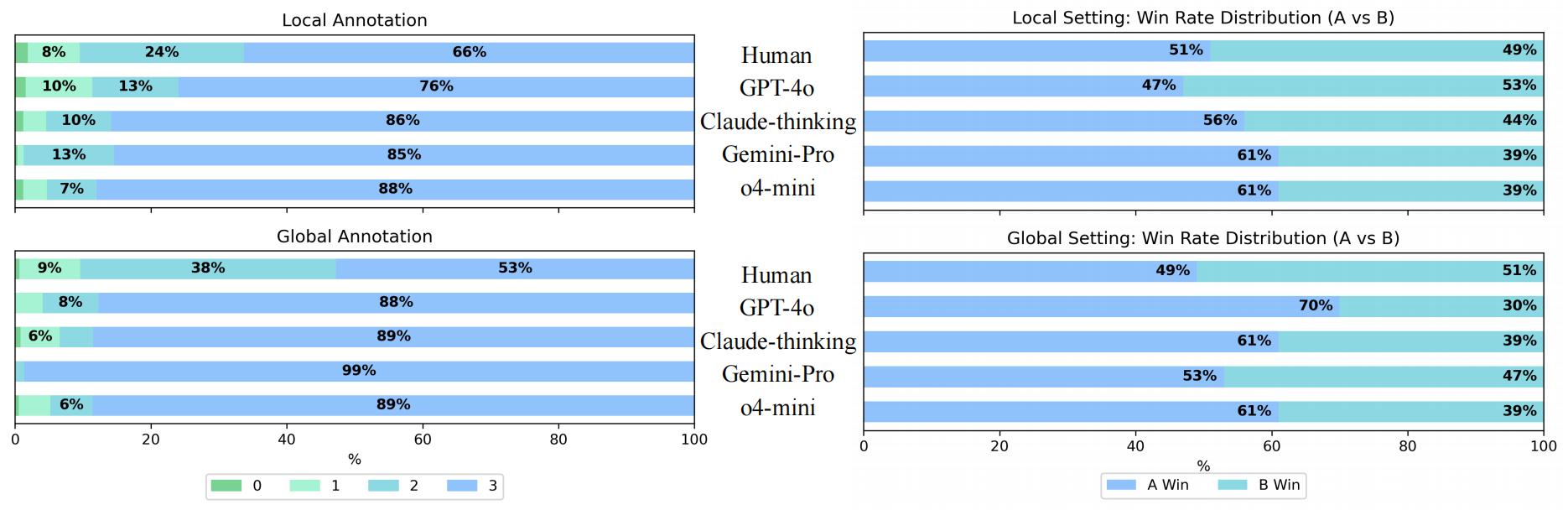
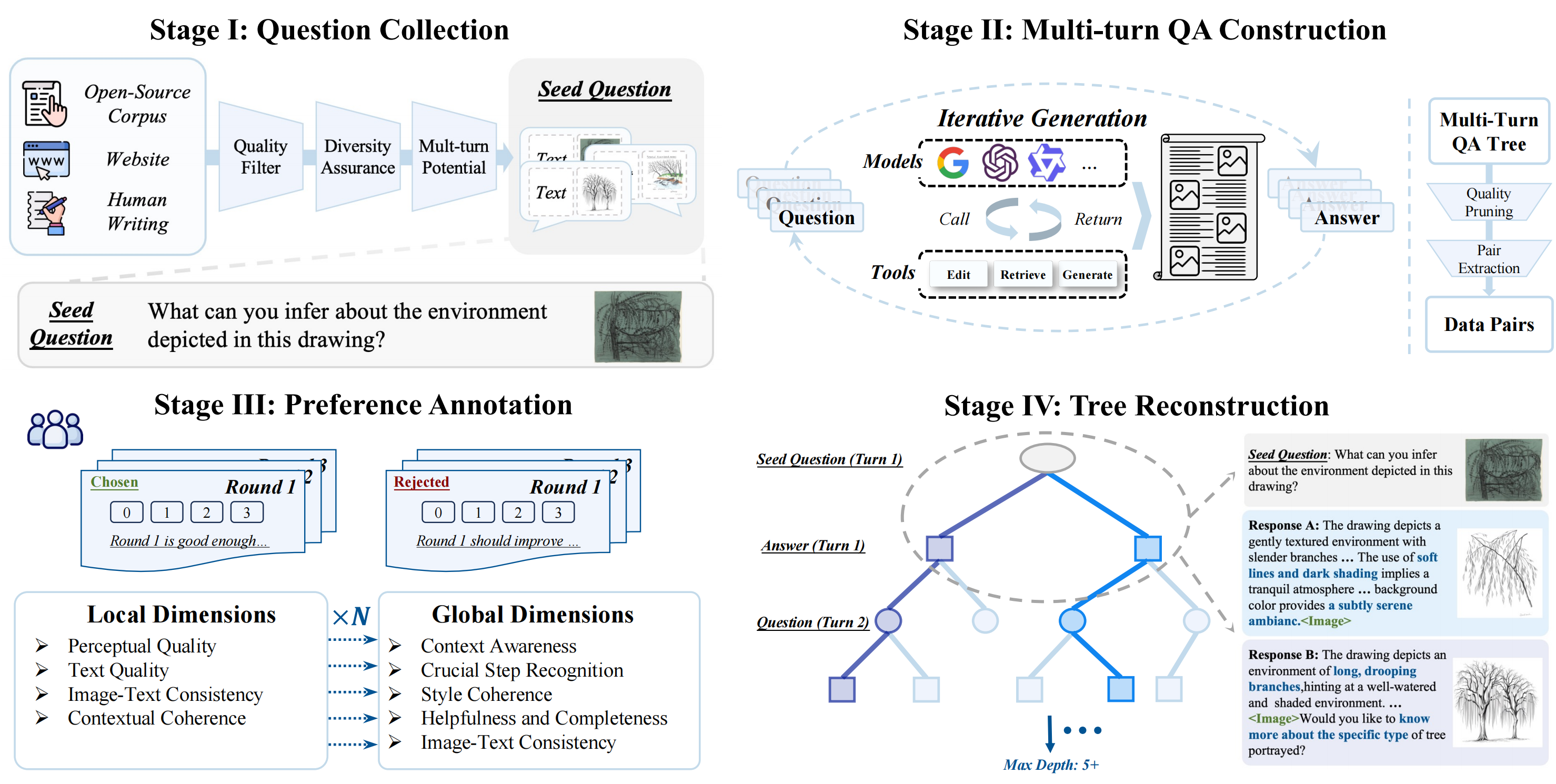

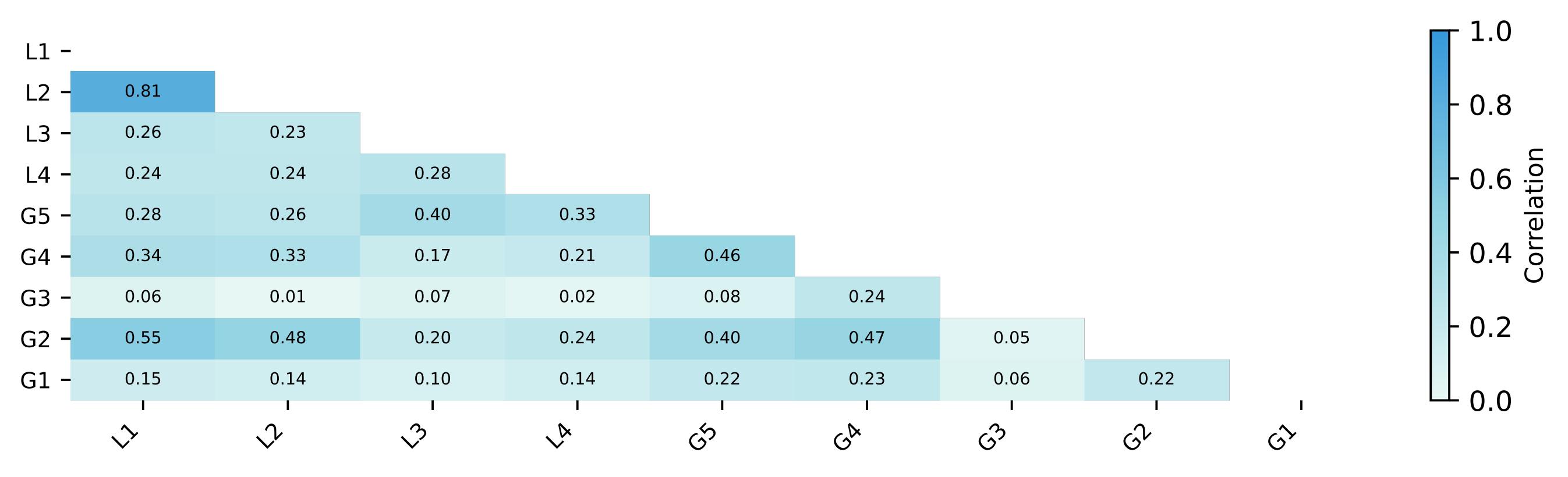

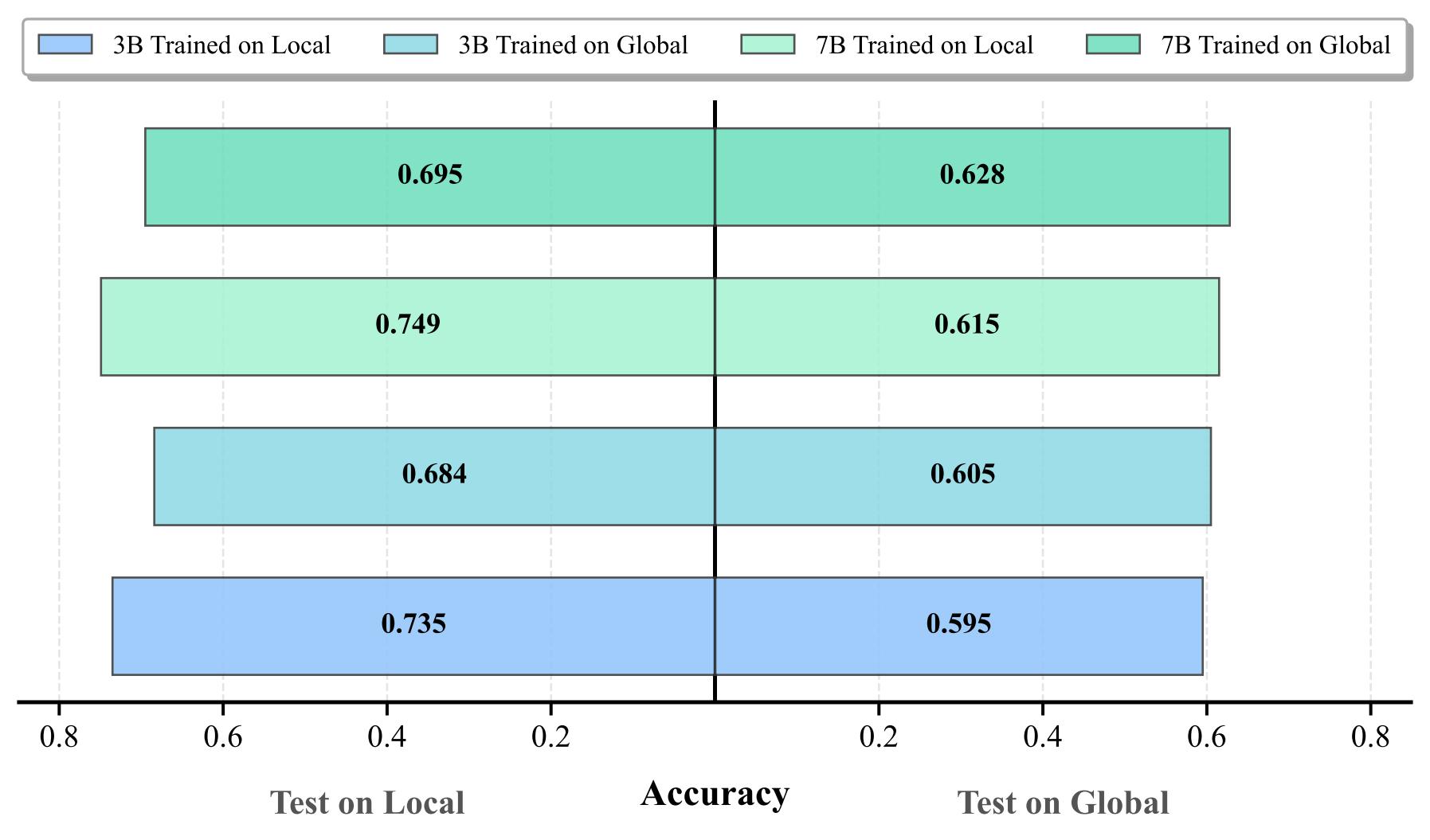
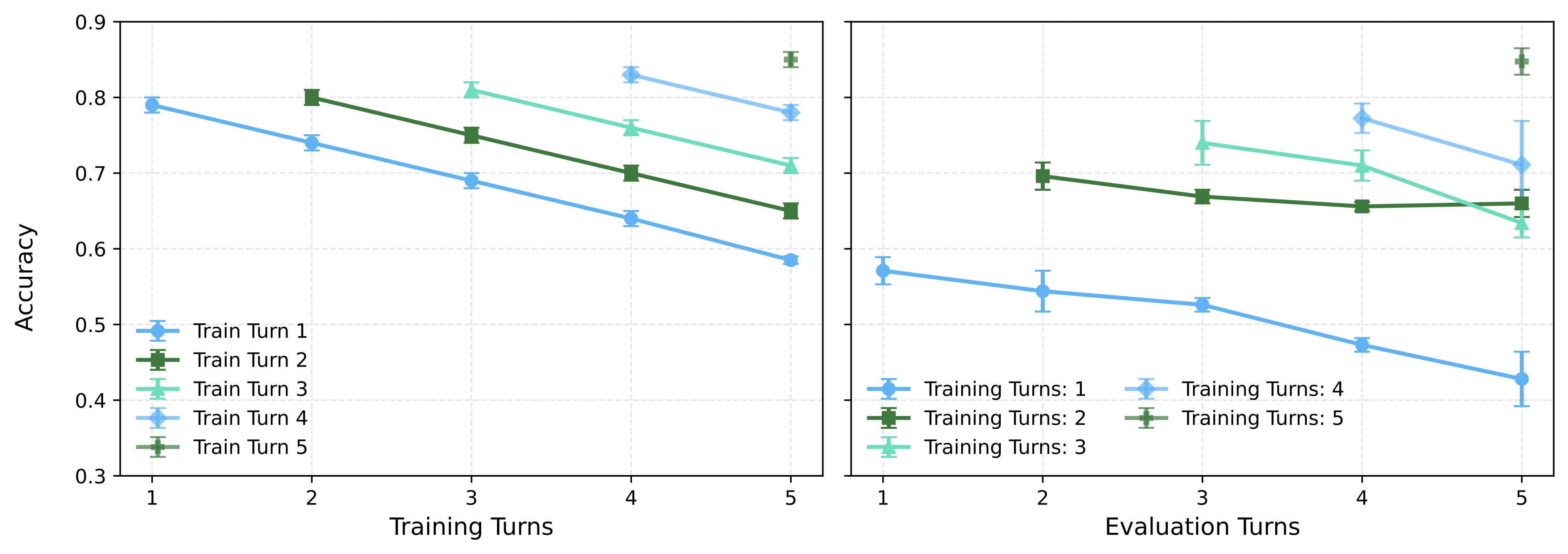
| Settings | MLLMs | Local Setting | Global Setting | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| L1 | L2 | L3 | L4 | Avg. | G1 | G2 | G3 | G4 | G5 | Avg. | ||
| Scoring Evaluation | Gemini-Flash* † | 0.346 | 0.107 | 0.119 | 0.173 | 0.186 | 0.163 | 0.042 | 0.051 | 0.246 | 0.005 | 0.101 |
| Gemini-Flash* (+reason) | 0.361 | 0.072 | 0.122 | 0.168 | 0.181 | -0.038 | 0.083 | 0.139 | 0.199 | 0.048 | 0.086 | |
| GPT-4.1 | 0.264 | 0.095 | 0.242 | 0.269 | 0.218 | 0.215 | 0.216 | 0.084 | 0.044 | 0.049 | 0.122 | |
| GPT-4.1 (+reason) | 0.281 | 0.094 | 0.272 | 0.271 | 0.229 | 0.215 | 0.255 | 0.217 | 0.216 | 0.050 | 0.191 | |
| GPT-4o | 0.291 | 0.131 | 0.277 | 0.268 | 0.242 | 0.254 | 0.167 | 0.137 | 0.139 | 0.069 | 0.153 | |
| GPT-4o (+reason) | 0.290 | 0.091 | 0.252 | 0.280 | 0.228 | 0.183 | 0.243 | 0.194 | 0.086 | 0.072 | 0.156 | |
| Gemini-Pro* | 0.273 | 0.079 | 0.258 | 0.168 | 0.194 | 0.285 | 0.240 | -0.024 | 0.235 | 0.145 | 0.176 | |
| Gemini-Pro* (+reason) | 0.274 | 0.070 | 0.304 | 0.211 | 0.215 | 0.239 | 0.267 | 0.195 | 0.129 | 0.060 | 0.178 | |
| Claude-thinking* | 0.299 | 0.044 | 0.262 | 0.229 | 0.209 | 0.172 | 0.140 | 0.175 | 0.150 | 0.069 | 0.141 | |
| Claude-thinking* (+reason) | 0.291 | 0.023 | 0.254 | 0.214 | 0.196 | 0.207 | 0.260 | 0.183 | 0.155 | -0.001 | 0.161 | |
| o4-mini | 0.334 | 0.062 | 0.306 | 0.134 | 0.209 | 0.169 | 0.161 | 0.120 | 0.096 | 0.028 | 0.115 | |
| o4-mini (+reason) | 0.326 | 0.056 | 0.322 | 0.151 | 0.214 | 0.215 | 0.229 | 0.347 | 0.137 | 0.016 | 0.189 | |
| Pair Comparison | GPT-4.1 | 0.541 | 0.589 | 0.508 | 0.484 | 0.531 | 0.540 | 0.520 | 0.530 | 0.590 | 0.563 | 0.549 |
| GPT-4.1 (+reason) | 0.550 | 0.584 | 0.501 | 0.521 | 0.539 | 0.520 | 0.520 | 0.477 | 0.513 | 0.540 | 0.514 | |
| GPT-4o | 0.513 | 0.488 | 0.499 | 0.510 | 0.503 | 0.560 | 0.517 | 0.550 | 0.543 | 0.470 | 0.528 | |
| GPT-4o (+reason) | 0.500 | 0.537 | 0.511 | 0.509 | 0.514 | 0.542 | 0.490 | 0.545 | 0.522 | 0.528 | 0.525 | |
| Gemini-Pro* | 0.533 | 0.521 | 0.496 | 0.533 | 0.521 | 0.562 | 0.566 | 0.523 | 0.505 | 0.505 | 0.532 | |
| Gemini-Pro* (+reason) | 0.526 | 0.528 | 0.513 | 0.514 | 0.520 | 0.548 | 0.562 | 0.495 | 0.522 | 0.538 | 0.533 | |
| Claude-thinking* | 0.561 | 0.568 | 0.508 | 0.502 | 0.535 | 0.539 | 0.523 | 0.518 | 0.521 | 0.528 | 0.526 | |
| Claude-thinking* (+reason) | 0.567 | 0.550 | 0.506 | 0.519 | 0.536 | 0.512 | 0.522 | 0.512 | 0.547 | 0.512 | 0.521 | |
| o4-mini | 0.556 | 0.549 | 0.508 | 0.536 | 0.537 | 0.552 | 0.498 | 0.522 | 0.518 | 0.495 | 0.517 | |
| o4-mini (+reason) | 0.521 | 0.564 | 0.522 | 0.513 | 0.530 | 0.534 | 0.510 | 0.507 | 0.512 | 0.483 | 0.509 | |
 InterMT: Multi-Turn Interleaved Preference Alignment with Human Feedback
InterMT: Multi-Turn Interleaved Preference Alignment with Human Feedback
NeurIPS 2025 Spotlight